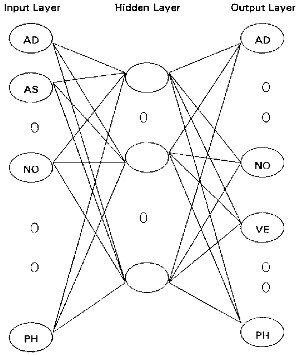
Figure 1. Structure of the Neural Network
Mei Yuan (袁梅), Richard A. Kunst, and Frank L. Borchardt
Introduction
The most user-friendly way of typing Chinese on a personal computer is through entering it phonetically, as one would speak, by typing in a standard Roman transcription such as pinyin, and letting the computer do the work of looking up the pinyin words in an internal dictionary which contains correspondences between pinyin and Chinese Hanzi characters, then converting them instantly into the correct characters. This phonetic conversion method is the main Chinese input method for both courseware authors and students in the WinCALIS 2.0 Computer Assisted Language Learning (CALL) authoring system for Windows. But there is an inconvenience to the pinyin-based typing of Chinese because there are many homophones, words which sound alike, even when tones are taken into account. In such cases, the computer can only present the typist with a selection list and ask him to choose the desired word. (If Chinese were English, the typist would enter the phonetic transcription "tu," and be presented with the homophone selection list "to," "two," and "too.")
Sometimes the typist must search and choose from among dozens of Chinese characters. Homophones are most numerous for the single-syllable words which form the high-frequency core vocabulary of any language. Choosing from among a list of homophones is obviously inefficient. Some efforts have been made to deal with this problem, such as maintaining frequency lists and typing in longer contexts of combinations of syllables. These are made use of extensively also in WinCALIS 2.0. Here we would like to introduce a new approach to deal with cases where these other approaches fail: a neural network which is used to predict the most likely word.
Perhaps because our software is used to assist in language teaching, it is easy to imagine that syntax could help to predict. But the problem is that natural language is so flexible that it can't be defined clearly like a computer language. The concept of the neural network has been talked about for several years and has been explained in various ways. Here, we would like to explain a neural network by drawing an analogy. There are two ways to learn language: one is native language learning, the other is foreign language learning. The difference between these is just like that between the neural network and the traditional computer. Foreign language learning, by which we mean learning at school, starts with character, pronunciation, sentence structure, and so on. That means the teacher knows all the details, and teaches what to do and how to do it. This is like the traditional computer algorithm it does what people know definitely how to do and what will happen. But the neural network is designed to simulate the intelligence of human beings and to tell us how to do something after it learns by itself. It is similar to native language learning. Parents hardly are concerned at all about syntax, but the child will speak perfectly after listening and listening. Parents never talk about any rules of language, but the child will follow these rules even though he never notices them. Similarly we provide to the neural network only samples of Chinese text, but no rules, and after learning by itself, it will know what to do. It will know which homophone is the right one to fit in a certain context, just as the English speaker knows which form of /tu/ fits in a certain context. Thus a neural network looks as if it is very suitable to deal with the problem of Chinese input.
Structure
The structure of the neural network in WinCALIS is shown as Figure 1.
There are 23 nodes both in the input layer and the output layer. Each of the nodes stands for one word class category, like "noun," "verb," "adverb," etc. There are 7 nodes in the hidden layer. The input is one certain word class, and the output indicates the different probabilities of any of the 23 word classes appearing after that word class.
Training
To train the neural network is to find an appropriate weight matrix according to the training material. We used the generalized delta rule as the learning algorithm for the network. The training material consists of many sample sentences. While the typists who compiled the training material typed Chinese, a file including all the information about word classes was automatically created. For example, when the following sentence was typed:
the corresponding wordclass string "PR Vt NU ME NO EP" (which stands for pronoun, verb-transitive, number, measure, noun, and period) was also saved.Wǒ yǒu sānbǎ yàoshi.
我有三把钥匙。
I have three (measure for keys) keys.
When the neural network was trained, any two adjacent word classes were used as a pair of Input and Target. Thus in the sentence above, the pairs of Inputs and Targets are (PR Vt) (Vt NU) (NU ME) (ME NO) (NO EP). When the neural network gets a word class input, it converts the word class to a vector I = (i1,i2,i3 ... i23) by giving a high value to the node corresponding to that word class, and giving a low value to all the others. So if the input word class is AD (adverb), the input vector is I = (0.999, 0.001, 0.001 ... 0.001). The target is converted in the same way.
After it gets its input, the neural network calculates step by step from the input layer to the output layer.
H =Wh.I ;
O =Wo.H ;
(Here, H is Hidden, I is Input, O is Output)
Because the output will be the probability, the value of which ranges from 0 to 1, we used the sigmoid function f(x) = 1/(1+e-x).
h1Then it compares the output with the target and gets the errors. Using these errors it back-propagates step by step from the output layer back to the input layer, in order to adjust the weight matrixes.
h2
. = H = f(Wh.I )
. hk:=
h7o1
o2
. = O = f(Wo.H )
.
o23
1After completing those steps for a single Input-Target pair, the next Input-Target pair is used to repeat the above steps, then the next, then the next until the whole material is learned (about 60,000 word class tokens for the whole material).
2
. = = (T -O ).f'(O )
.
23
f'(x) = (1/(1+e-x))' = f(x).(1-f(x))
h1
h2
. = h= .Wo.f'(H )
.
h7
W(t+1)= W(t) + . .(I )T+ . W(t-1)
We did not use masses of training material, so the neural network had to occasionally re-learn the same material. When the table resulting from a trial run had only a few changes after one more training, we considered that the weight matrixes had converged sufficiently. Below is the table of weight matrices which WinCALIS uses now.
| Adverb | AD ( VE 0.6700 VA 0.0826 CV 0.0769 AD 0.0713 ) |
| Adstative | AS ( AJ 0.9750 VE 0.1478 NO 0.0594 ) |
| Adjective | AJ ( NO 0.3135 VE 0.1979 PS 0.1131 EC 0.0885 EP 0.0802 ) |
| Coverb (Prep.) | CV ( NO 0.5748 VE 0.1640 ) |
| Interjection | IN ( NO 0.4567 VE 0.1553 AJ 0.0780 ) |
| Movable. Adv. | MA ( NO 0.5776 VE 0.2537 AJ 0.0594 ) |
| Measure | ME ( NO 0.4664 VE 0.1407 AJ0.0801 ) |
| Noun | NO ( NO 0.3253 VE 0.1812 EC 0.0741 EP 0.0686 PS 0.0592 AD 0.0569 ) |
| Number | NU ( ME 0.5017 NU 0.3380 VE 0.1672 NO 0.0751 ) |
| Particle | PA ( EP 0.3095 NO 0.1819 NU 0.1483 EC 0.1085 VE 0.0513 ) |
| Ordinaliz. Part. | PO ( NU 0.8621 VE 0.1375 ) |
| Subord. Particle | PS ( NO 0.6858 AJ 0.0894 ) |
| Prevrb.Sub.Part. | PT (VE 0.5069 AJ 0.2129 NO 0.1655 CV 0.1092 AD 0.0529 PS 0.0504 ) |
| Pstvrb.Sub.Part. | PU ( AJ 0.5234 VE 0.1836 NO 0.1256 AD 0.1092 ) |
| Specifier | SP ( ME 0.6236 NU 0.1553 NO 0.0875 ) |
| Stative Verb | SV ( NO 0.2955 VE 0.1879 ) |
| Aux. Verb | VA ( VE 0.6698 AJ 0.1123 CV 0.0839 AD 0.0517 ) |
| Verb | VE ( NO 0.3315 VE 0.1636 NU 0.0706 EC 0.0624 ) |
| Verb-Complmnt. | VC ( VE 0.2961 NO 0.1656 ) |
| Verb-Obj.Cmpd. | VO ( VE 0.2391 ) |
| Period | EP ( NO 0.6524 VE 0.1531 AD 0.0588 MA 0.0563 ) |
| Comma | EC ( VE 0.2786 NO 0.2205 AD 0.1555 AJ 0.0731 MA 0.0559 ) |
| Phrase | PH ( VE 0.4510 AD 0.0750 NO 0.0581) |
This table indicates the probability of one word class being followed by another. For example:
The neural network will function when the typist presses the space bar, which serves as a convert key after he finishes typing a word in pinyin transcription and any homophones are found after a search of the WinCALIS internal dictionary of pinyin-Chinese character correspondences. It gets the word class of the preceding already converted word from the text buffer, does its calculations, and gets the list of probable following word classes. Then the word classes of the homophones are compared with this list. If only one word has the word class belonging to the list, it is considered as the one the typist wanted as in automatically converted without any user intervention. For example, in the sentence cited above,
in the WinCALIS internal Chinese dictionary, yàoshi has the entries:Wǒ yǒu sānbǎ yàoshi.
我有三把钥匙。
I have three (measure for keys) keys.
Bǎ is a measure which may be followed by NO (noun), VE (verb), AJ (adjective), but not MA (movable adverb), so the neural network predicts it is the yàoshi meaning "key" 钥匙.
要是 "if" MA (movable adverb) 钥匙 "key" NO (noun)
If more than one match is found, the most probable word will be compared with the second probable but different word. If the difference of probability is significant, the neural network will be sure that the most probable word is the one the typist wants. Consider the word jìn in the following example:
In the dictionary, the syllable jìn has the word entries:hěn jìn
很 jìn
very - ?
Hěn is AS (adstative), so AJ gets the probability of 0.975, but VE and NO only get 0.1478 and 0.0594, respectively. The difference is very high, so the neural network is sure it is the jìn meaning "near" 近.
进 "come in" VE 近 "near" AJ 劲 "energy" NO
But in another example,
qī qīin the WinCALIS internal dictionary, qī has the word entries:
七 qī
seven - ?
Qī 七 is a NU (number), so it may be followed by both another NU (number) and ME (measure), and the difference of probability between NU and ME (which is 0.5017 - 0.3380 = 0.1637) is considered as insignificant. The neural network will not predict in this situation. In fact, both qī qī (nián) 七七(年) "(the year) seventy-seven" and (dì) qī qī 第七期 "seven(th) period" are possible.
七 "seven" NU 期 "period" ME
Enhancements
When we analyzed the neural network's training and operation, it also suggested to us to regroup the word classes. We originally had combined all the verbs Vi (verb-intransitive), Vt (verb-transitive), Va (verb-auxiliary), and Vr (verb-resultative) in one category VE. Because the word class NO (noun) was more likely to follow this mega-word class VE (verb) than any others, when one typed an auxiliary verb+main verb phrase like néng tīng "can listen," the neural network always favored the noun for the second word, choosing the nonsensical 能厅 "can hall," instead of the desired 能听 "can listen." We thought about the difference between Va (auxiliary verbs) and regular verbs and decided to separate the Va from the VE category. It is wonderful that the neural network confirms that the lists of probable words after regular VE and Va are totally different. This is true also for the newly created word class AS (adstative) from the more general word class AD (adverb), and PT (pre-verbal subordinating particle de 地) and PU (post-verbal subordinating particle de 得), differentiated from PS (subordinating particle de 的).
Conclusions
The network usually selects correctly by providing the output with highest probability in that context: the likelihood that it will offer a correct choice in second or third place, if first place is in error, approaches 100%. Considering that the system allows for twenty other outputs, this result is highly significant. The network has "learned" the allowable and unallowable sequences in Chinese syntax and applies that "learning" to the actual task of typing Chinese in phonetic representation.
Presenters' Biodata
Mei Yuan (袁梅) was a visiting researcher at the Humanities Computing Facility of Duke University. She received a B.E. degree in Computer Science from Zhejiang University and an M.S. degree in Computer Assisted Design from the Shanghai Maritime Institute. She investigated the design and application of back-propagation networks in Chinese natural language processing.
Frank L. Borchardt, Ph.D. (deceased), was Professor of German at Duke University and director of the Duke University Computer Assisted Language Learning (DUCALL) Project.
Richard A. Kunst, Ph.D., was Research Associate in the Duke University Computer Assisted Language Learning (DUCALL) Project.
Contact Information
The Authors c/o
The Humanities Computing Laboratory
109 Lariat Ln. Suite B
Chapel Hill, NC 27517 USA
Tel: +1 (919) 656-5915
E-mail: rkunst@humancomp.org
WWW: http://www.humancomp.org